0、前言
将学习过程中遇到的知识点做一个总结归纳。
- ctrl+shift+v 本地预览.md文件 唉… 本来想复制点东西..偶然发现了这么个组合快捷键。
1、服务器命令行运行之诡怪
很有意思,下午跟师姐了解了一下课题内容具体细节,因为暑假实习掌握了一些基础内容,现在学可能多少入门会快一点,晚上ssh服务器之后顺利找到程序所在位置,run demo应该是最爽的了吧
还行,上来就报错pygame找不到了,我:???
1
2
3
4
5
6
$pip3 install pygame --user
$... success ...
$python3
Python 3.6.8 (default, Jan 14 2019, 11:02:34)巴拉巴拉
>> import pygame
wrong!
$python3 这一条指令软连接到系统安装默认的python版本,反复查验后pygame安装给了python3.7版本??查看了一下/usr/bin/python* 并没有找到python3.7 这时候奇怪了,从清华源下载怎么就这样了…期间尝试了改默认python版本的软链接、官网下载pygame包本地安装、甚至删除python3.7版本,均无效..
1
2
jiafan@TJDL4:~/uct$ python3.7 Python 3.7.2 (default, Mar 2 2019, 10:56:35)[GCC 5.4.0 20160609] on linux Type "help", "copyright", "credits" or "license" for more information.
>>> import pygame pygame 1.9.6 Hello from the pygame community. https://www.pygame.org/>>>
所以突发奇想直接指定python版本即可…
2、初探流程
忙完手头的活补充了基本知识之后开始尝试大致了解代码。
大致流程如下所示
1、train_episode和test_episode目录先各收集到5个episode, /planet/control/random_episodes.py def random_episodes() |初始化def _initial_collection() | /planet/training/utility.py def collect_initial_episodes()中调用 2、然后开始5万步,每一步从train_episode取数据, /planet/scripts/configs.py ----> def _training_schedule(config, params): 3、计算loss。 /planet/training/define_model.py ----> train_loss = tf.cond() 4、去求gradient,再planning出一个episode。 5、5万步后是100步的test phase,会从test_episode得数据 /planet/scripts/configs.py ----> def _training_schedule(config, params): 6、不求loss 不求gradient, /planet/training/define_model.py ----> train_loss = tf.cond() 7、之后planning出一个episode. /planet/training/test_running.py ---> with tf.variable_scope('simulation')
为了学习准确的潜在动力学模型,google团队引入了:
循环状态空间模型:具有确定性和随机性成分的潜在动力学模型,允许根据稳健的计划预测各种可能的未来,同时记住多个时间步骤的信息。实验表明,这两个组件对于高规划性能至关重要。
潜在的超调目标:将潜动力模型的标准训练目标推广到训练多步预测,通过在潜空间中加强一步预测和多步预测的一致性。这产生了一个快速和有效的目标,提高了长期预测,并与任何潜在序列模型兼容。
总结:
虽然预测未来图像允许教授模型,但编码和解码图像(上图中的梯形)需要大量计算,这会减慢计划。然而,在紧凑的潜在状态空间中的规划是快速的,因为我们仅需要预测未来的奖励而不是图像来评估动作序列。
例如:智能体可以想象球的位置及其与目标的距离将如何针对某些动作而改变,而不必使场景可视化。
这允许在智能体每次选择动作时能够比较1万个想象的动作序列(之后的好多步动作,这里是12步)和并对回报大小进行计算,最后执行找到的最佳序列的第一个动作,执行结束后并对之后的动作重新进行计划。
3、解决ubuntu运行不友好的问题
实验室的师兄们使用Mobaxterm远程连接服务器之后文件移动以及pycharm调试特别方便,那么ubuntu是不是就特别不方便了?问题不大。
期初因为命令行run报错太多,pygame运行缺少video报错的问题,就把问题归咎于命令行的问题…于是搞了个软件来模拟win链接服务器,恩,是这个Asbru, 相对不太友好的是文件的传输还是需要scp指令,效果见下图:
不过问题还好是解决了,命令行报video的错,asbru报audio的错stackoverflow解决办法 添加pygame的初始化。
asbru客户端下问题确实解决了,出于好奇便想彻底解决命令行下运行报错的问题,嘿嘿,试了试把文件里面不调用音频,不过只有同时打开asbru的情况下才能正常运行…下面这个图看起来还是可以的吧。
4、代码中关于使用GPU的 RuntimeError: to is not supported on TracedModules
问题很简单 就小小贴一下 pytorch报错 使用不当报错 不知道源代码怎么错误写成了net.to(device=args.device)
5、系统地学习Tensorflow
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
class Critic(object):
def __init__(self, sess, state_dim, action_dim, learning_rate, gamma, replacement, a, a_):
self.sess = sess
self.s_dim = state_dim
self.a_dim = action_dim
self.lr = learning_rate
self.gamma = gamma
self.replacement = replacement
with tf.variable_scope('Critic'):
# Input (s, a), output q
self.a = tf.stop_gradient(a) # stop critic update flows to actor
self.q = self._build_net(S, self.a, 'eval_net', trainable=True)
# Input (s_, a_), output q_ for q_target
self.q_ = self._build_net(S_, a_, 'target_net', trainable=False) # target_q is based on a_ from Actor's target_net
self.e_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Critic/eval_net')
self.t_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Critic/target_net')
#下一步的状态和当前的动作 这里变了:算出真实的Q值(max) 定义变量
with tf.variable_scope('target_q'):
self.target_q = R + self.gamma * self.q_
# 平方差计算损失 (R + self.gamma * self.q_-self.q)^2 这里的q是eval_net预估的q值 定义变量
with tf.variable_scope('TD_error'):
self.loss = tf.reduce_mean(tf.squared_difference(self.target_q, self.q))
with tf.variable_scope('C_train'):
self.train_op = tf.train.AdamOptimizer(self.lr).minimize(self.loss)
with tf.variable_scope('a_grad'):
self.a_grads = tf.gradients(self.q, a)[0] # tensor of gradients of each sample (None, a_dim)
# DQN每隔固定步数更新参数 定义变量
if self.replacement['name'] == 'hard':
self.t_replace_counter = 0
self.hard_replacement = [tf.assign(t, e) for t, e in zip(self.t_params, self.e_params)]
# DDPG每一步都稍微更新参数 定义变量
else:
self.soft_replacement = [tf.assign(t, (1 - self.replacement['tau']) * t + self.replacement['tau'] * e)
for t, e in zip(self.t_params, self.e_params)]
def _build_net(self, s, a, scope, trainable):
with tf.variable_scope(scope):
init_w = tf.random_normal_initializer(0., 0.1)
init_b = tf.constant_initializer(0.1)
with tf.variable_scope('l1'):
n_l1 = 30
w1_s = tf.get_variable('w1_s', [self.s_dim, n_l1], initializer=init_w, trainable=trainable)
w1_a = tf.get_variable('w1_a', [self.a_dim, n_l1], initializer=init_w, trainable=trainable)
b1 = tf.get_variable('b1', [1, n_l1], initializer=init_b, trainable=trainable)
net = tf.nn.relu(tf.matmul(s, w1_s) + tf.matmul(a, w1_a) + b1)
with tf.variable_scope('q'):
q = tf.layers.dense(net, 1, kernel_initializer=init_w, bias_initializer=init_b, trainable=trainable)
return q # maxQ(S',a)
def learn(self, s, a, r, s_):
self.sess.run(self.train_op, feed_dict={S: s, self.a: a, R: r, S_: s_})
if self.replacement['name'] == 'soft':
self.sess.run(self.soft_replacement)
else:
if self.t_replace_counter % self.replacement['rep_iter_c'] == 0:
self.sess.run(self.hard_replacement)
self.t_replace_counter += 1
with tf.variable_scope(‘target_q’): # 往里面加入内容 tf.layers.dense() # 定义一层网络 self.sess.run() # 执行前面初始化过的变量所在函数
—————–华丽分割线——————
在开始学习之前,最好对机器学习有一个大致的了解。相比于市面上的很多书籍,吴恩达的网课应该是最好不过的了,特别是CNN网络的讲解非常透彻,当初看了那么多博客回过头来看他的Slides才发现好多坑都填平了。
斯坦福大学推出的CS20对于我个人来说是非常合适的,首先从基本的Tensorflow语句用法入手,大致对“图”有了解,进而讲解了CNN、GANS(这里推荐B站7月在线的网课)、VAE(自动化所黄怀波)、RNN,课后作业是填空类型实操。
6、十一结束 RNN深入学习
十一的前四天过得很充实,看了两天网课跟pdf仔细打了下基础知识,临开学前刷知乎发现了YJango大佬之前发过的RNN、LSTM详解,抓紧码住!
RNN与LSTM关系:
如果把RNN比作是手机屏幕,而LSTM-RNN与GRU则可以说是手机膜。
在多次迭代过程中,大量非线性累积历史信息会造成梯度消失(梯度爆炸),就像是手机裸机使用时间长了把屏幕刮花。
而LSTM将信息的积累建立在线性自连接的memory cell之上,并靠其作为中间物来计算,好比是用手机屏幕膜作为中间物来观察手机屏幕;
输入门、遗忘门、输出门的过滤作用好比是手机屏幕膜的反射率、吸收率、透射率三种性质
LSTM公式:
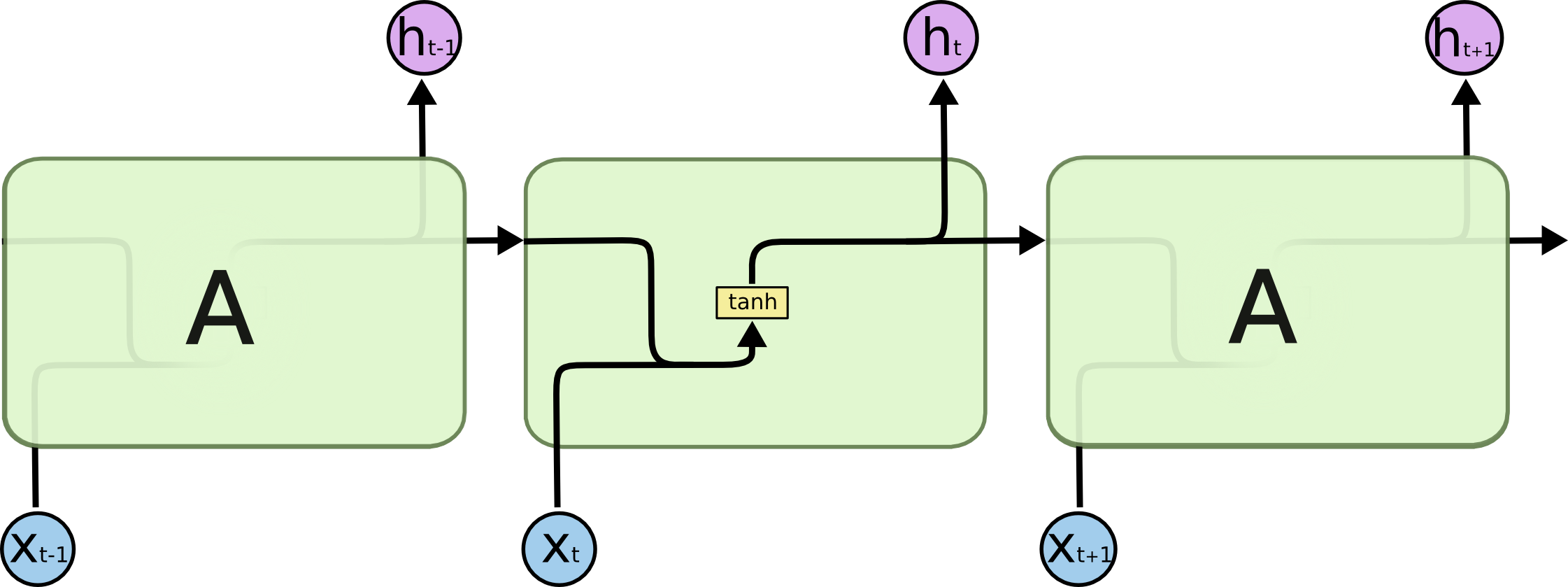
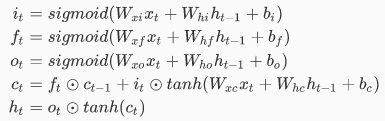 经典rnn过程:
经典rnn过程:
 LSTM:
LSTM:
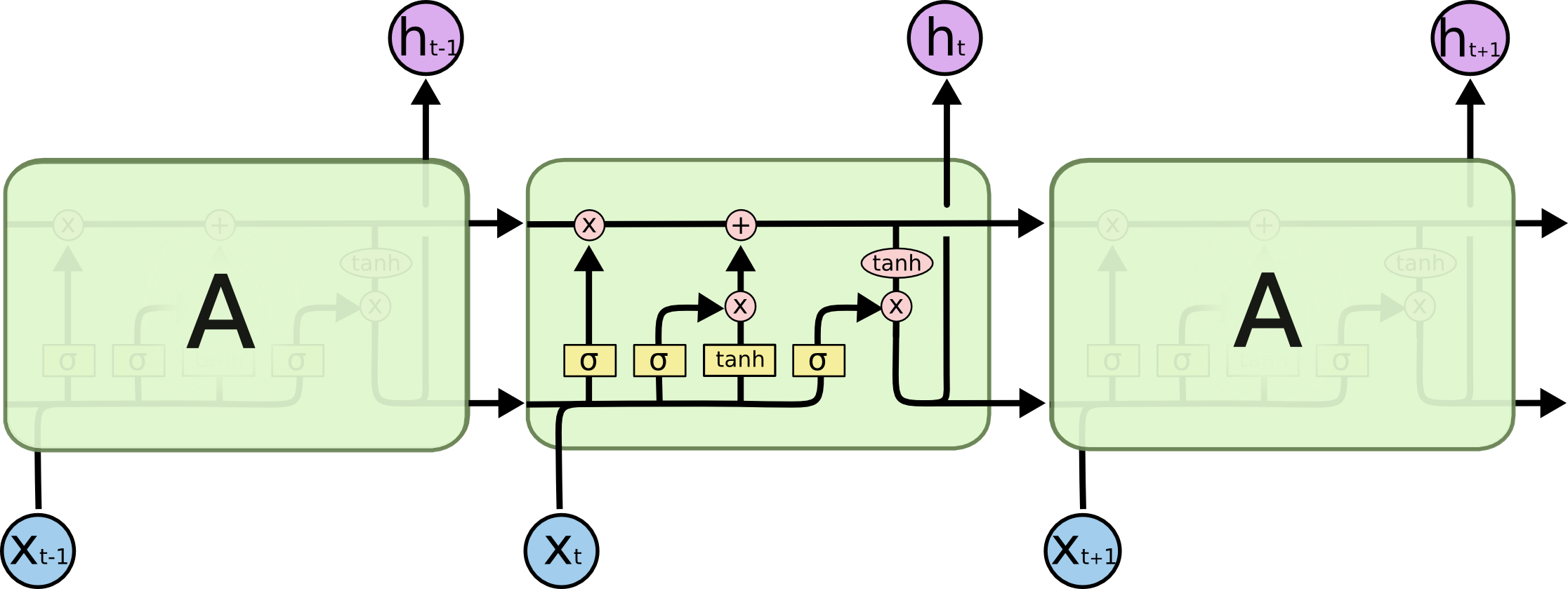 添加了一下标注 上面公式中的几个变量标出来:
添加了一下标注 上面公式中的几个变量标出来:
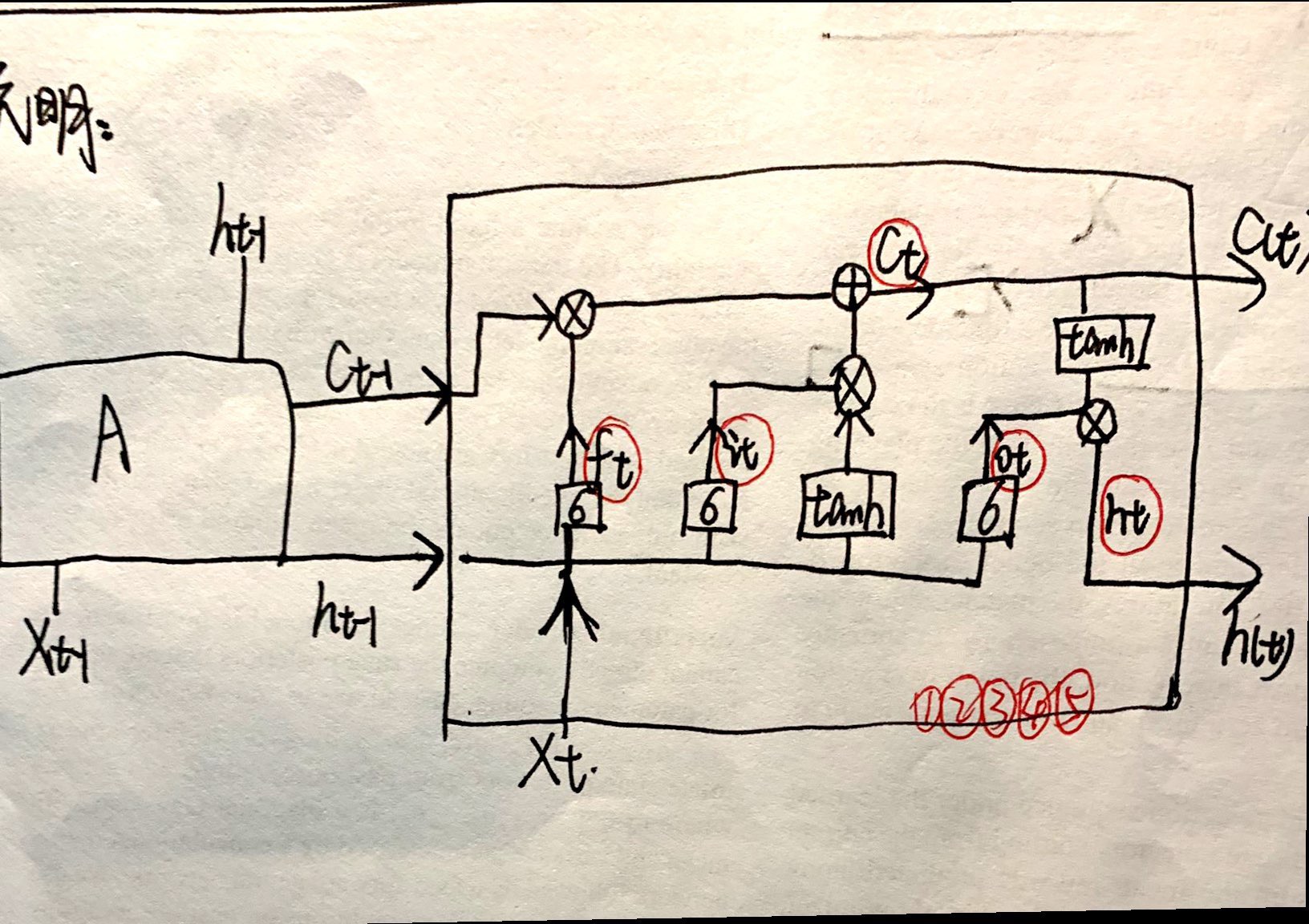 根据公式推导一遍确实理解的更加深刻,大佬666
根据公式推导一遍确实理解的更加深刻,大佬666
6、再进一步 交叉熵损失函数(CEEF)的计算
计算分类问题的时候使用交叉熵算法能够快速有效地得到较为准确的判断条件,文章·从常见的分类误差与均方误差计算结果来进行比较,通过已知概率对所需分类事件进行对数计算求和后得到预测的结果。至于计算方法与具体细节文章中已经做过了详细的介绍。
交叉熵算法计算的损失经过描点画图后得到了一个类似于反比例的凸函数,所以理论上存在最优解:
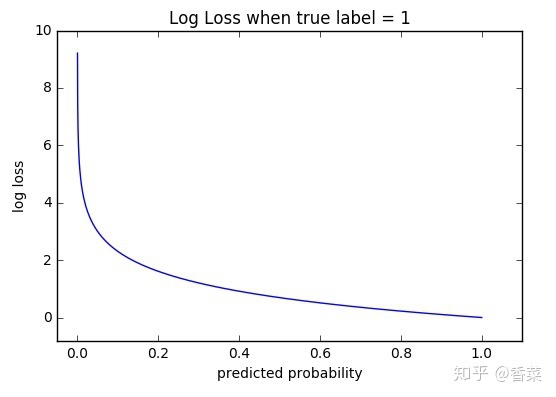 注意:文章中所提到的log均以10为底。
注意:文章中所提到的log均以10为底。
7、最近在深度方面没有多做研究
不只是玩了一玩..还有准备下考试和期中稍稍复习复习。
最近在看莫凡的reinfocement learning